Excelのデータを見やすくダッシュボード化したい!と思うことはありませんか?
それも、Excelでグラフを表示させたりするのでは無く、かと言ってお金のかかるソフトを使わずにできないだろうか?とお考えの方
Pythonのライブラリ、StreamlitとPlotlyを使えばインタラクティブなグラフを配置したダッシュボードが驚くほど簡単に作れます!
という事で今回は、Streamlitを使った事の無い人でも分かるように、その基本的な使い方なども説明しつつ、ダッシュボードを作っていきたいと思います。
前編と後編の2回に分けて、初心者にも分かりやすいように細かく説明していきます。
- Pythonを使ってエクセルのデータをグラフなどで見やすく表現したい人
- Pythonでダッシュボードを作ってみたい人
- Pythonで簡易的なWebアプリを作ってみたい人
- Pythonで簡易的なダッシュボードを作ります。
- Streamlitというライブラリを使って簡易的なWebアプリを作る方法が分かります
- エクセルから抽出したデータをPandasというライブラリで編集する方法が分かります
- Plotlyというライブラリでインタラクティブなグラフを作成する方法が分かります
今回作成するもの、使用するもの

開発環境
今回の記事で使用している開発環境を記しておきます。
- OS : Windows 10
- Pythonバージョン : 3.10.5
- 外部ライブラリ
- Streamlit : 1.12.2
- Pandas : 1.4.4
- Plotly : 5.10.0
- Openpyxl : 3.0.10 ※Pandasでエクセルファイルを読込むのに必要
使用するエクセルデータ
今回は下記のような中身のエクセルからデータを読込んでダッシュボード化します。
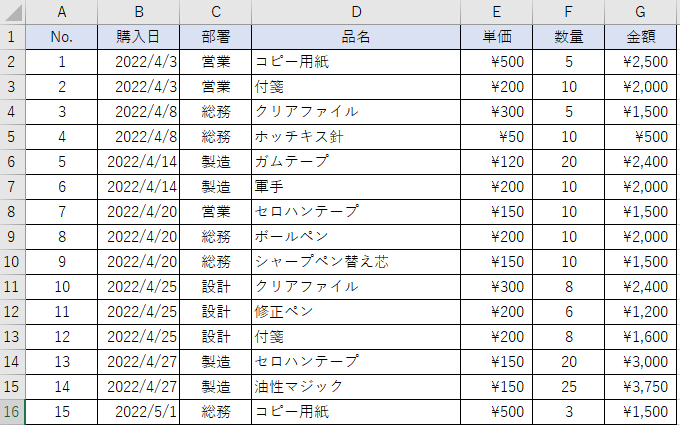
社内の「備品購入履歴」をイメージしたデータになっています。
購入した備品単位に、”購入日”・”購入部署”・”品名”・”金額” などが記録されています。
この記事で使用しているExcelデータを再現していただけるように
CSVデータを用意しました、GithubからダウンロードしてExcelに取り込んでください
上記リンク先の、緑色の Code ボタンから「Download ZIP」を選びダウンロード
ダッシュボードの完成イメージ
今回作成するダッシュボードは下記のようなイメージです。
上で紹介しているエクセルからデータを読込んで、表やグラフなどで表示させます。
ファイル構成
ファイル構成は非常に単純で、適当なフォルダの中に下記2つのファイルを置く想定です。

- Pythonファイル(これから書いていくプログラム)
- Excelファイル(上で説明した読み込む用のエクセル)
※フォルダ名、ファイル名は上記の通りでなくてもOK。
使用するライブラリ
今回使用するPythonの外部ライブラリを簡単に説明しておきます。
Streamlit
Streamlitは、PythonでWebアプリを簡単に作ることができるライブラリです。
Webアプリを作る場合、通常であればHTMLやCSSで画面の見た目を作ったり
JavaScriptで画面に動きを付けたりと、Python以外の言語も使って作ることになり
それらの知識が必要になりますし、作るのに時間がかかります。
しかしStreamlitを使えば、画面の見た目や動きはStreamlitが上手くやってくれますので
Pythonだけで速く簡単にWebアプリを作ることができます。
Plotly

Plotlyはグラフ描画用のライブラリです。
Pythonのグラフ描画ライブラリと言えばMatplotlibが有名ですが
Matplotlibに比べてPlotlyは、動きのあるインタラクティブなグラフを作ることができます。
今回は、簡単に書くことができる Plotly express を使用します。
Pandas
Pandasはデータ分析用ライブラリです。
エクセルのような表形式のデータを扱うのに便利なライブラリです。
インストール方法
ライブラリのインストールがまだの人は、事前に pip install でインストールしましょう。
pip install streamlit
pip install plotly
pip install pandas
pip install openpyxl※ 今回 openpyxl は表面上は使用しませんが、Pandasでエクセルデータを読込む時に裏で使用されますのでインストールしておきましょう。
データ取り込みと前準備
いよいよプログラムを書いていきます。
上で説明したように適当なフォルダ内にPythonファイルを作成しましょう。
※この記事では「streamlit_dashboard.py」というファイル名にしていますが、好きな名前を付けてもらってOKです。
ライブラリのインポート
まず最初にライブラリをインポートしましょう。
上で説明した3つの外部ライブラリと、日付データを扱うために datetime.date もインポートしておきます
from datetime import date
import pandas as pd
import streamlit as st
import plotly.express as pxエクセルの読み込み
では、Pandasを使ってExcel(注文履歴.xlsx)を読込みます。
PandasでExcelファイルを読込むには、read_excel()関数を使います。
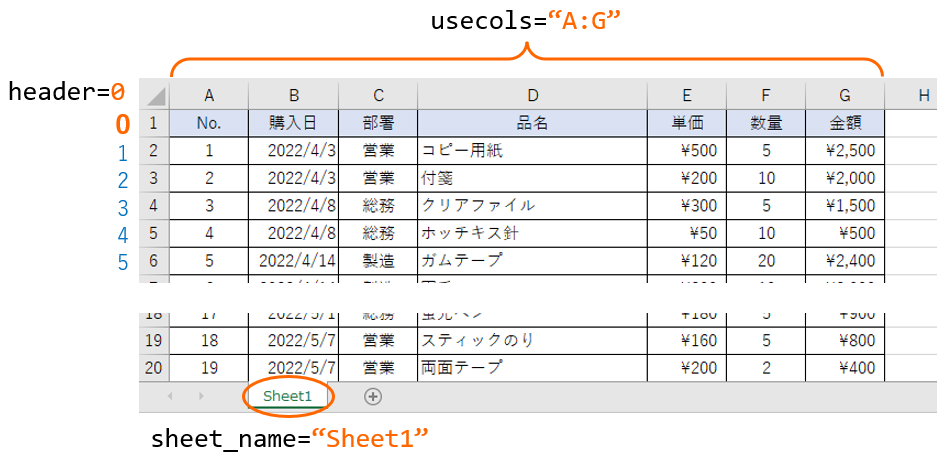
df = pd.read_excel("./注文履歴.xlsx", sheet_name="Sheet1", header=0, usecols="A:G")read_excel()
指定したExcelファイルをPandasのDataFrameに変換して返します。
上のコードでは、ExcelファイルのデータをDataFrameに変換して df という変数に代入しています。
- 第一引数:Excelファイルのパス
- sheet_name:読み込むシートを指示
- header:カラム名(列名)として使用する行
- usecols:読み込む列の範囲を指定
実は今回のExcelファイルの場合、第二引数以下(緑字の下3つの引数)は
指定しなくても問題なく読み込むことができるのですが
もし独自のExcelを使用される場合は指定が必要になるかもしれない為、あえて引数で読み込み範囲を指定するようにしています。
※第2~4引数が何を指しているかは下記をご覧ください。
読込んだデータの修正
読込んだデータを、後で扱いやすく(エラーなどが出ないように)するために修正します。
df = df.dropna() # 空白データがある行を除外
df[["単価", "数量", "金額"]] = df[["単価", "数量", "金額"]].astype(int) # 金額や数量を整数型に変換
df["月"] = df["購入日"].dt.month.astype(str) # "月"の列を追加
df["購入日|部署"] = df["購入日"].astype(str).str.cat(df["部署"], sep="|") # "購入日|部署" 列を追加空白行を削除
もし、読込んだExcelの表に空白のセルが混じっていると、PandasのDataFrameでは欠損値として扱われ
何か処理をする時に不具合を生じる事があるためここで削除しておきます。
欠損値の削除はDataFrameのdropna()メソッドが使えます。
df = df.dropna()上記のように書くと、df(ExcelデータのDataFrame)の中で空白(欠損値)がある行を削除できます。
データ型を変換
下記の行で、”単価”, ”数量”, ”金額” 列を int型(整数型)に変換しています。
データ型の変換は astype() メソッドで行います。
df[["単価", "数量", "金額"]] = df[["単価", "数量", "金額"]].astype(int)read_excel()は、Excel上の書式などから判断して自動で列ごとにデータ型を設定して読み込んでくれます。
ただ、今回のExcelは欠損(空白)セルを含んでいるため、整数は欠損値が扱えるfloat型(浮動小数点型)で取り込まれます
そこで手動にてint(整数)型へ変換しています。
欠損値を扱える整数型(Int64など)もありますが、ここでは考えずに進めます
月をあらわす列の追加
”購入日” の列から月の情報だけを取り出して “月” 列を追加します。
例) 2022/6/12 → 6
”購入日” 列は datetime型 で読み込まれており、Pandasのdatetime型列は後ろに .dt を付けるとpythonのdatetime型が持つメソッドなどを列全体に実行することができます
ここでは、month 属性で月だけを取り出しています。
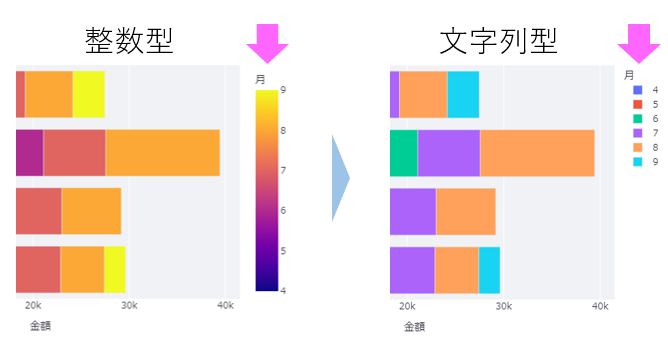
df["月"] = df["購入日"].dt.month.astype(str)更に、後ろに astype(str) を付けてstr型(文字列型)へ変換しています。
これは、そのままだと月情報が整数型で取り出されるのですが、グラフ表示には文字列型のほうが凡例が分かりやすく表示されるためです(下図)。
購入日と部署の組み合わせ列を追加
後ほど、同日の同部署の購入は1カウントで集計したいため
”購入日” と ”部署” を組み合わせた列を追加します。
例)「2022/5/16」「営業」 → 「2022/5/16|営業」
文字列データどうしを連結して新しい文字列を作るには、.str.cat() メソッドを使います。
df["カラム1"].str.cat(df["カラム2"], sep="|")
上記のように書くと カラム1の文字列 と カラム2の文字列 が “|” で連結されます。
df["購入日|部署"] = df["購入日"].astype(str).str.cat(df["部署"], sep="|")
- ”購入日” 列を取り出す
- str型(文字列型)に変換
- 文字列型の列は .str を付けると、列全体への処理が可能になる
- .cat() で ”部署” 列を 接合文字 ”|” で連結
- 以上の処理をしたものを ”購入日|部署” 列として追加
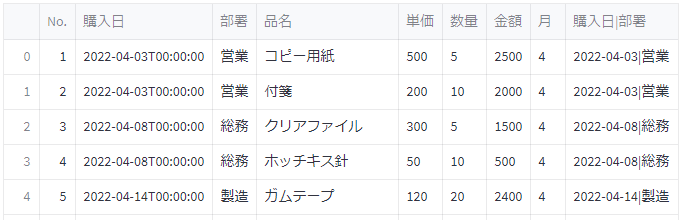
ここまでで出来上がったDataFrame
ここまでの処理で出来上がったDataFrameの中身を載せておきます。
右側の2列が、先ほど追加した列になります。
Streamlit でページ構築(タイトルと集計表示)
ここからはStreamlitを使ってダッシュボードを作っていきます
まずは、下記のようなタイトルと集計表示を作っていきましょう

streamlitのページ設定
streamlit のプログラムを書いていく前に、streamlitのページ設定をしましょう。
ページ設定は st.set_page_config() で行います。
ページ設定は必ずしなければいけないという事は無いです
設定する場合は、streamlitのプログラムを書く前にする必要があります
st.set_page_config(
page_title="備品購入ダッシュボード",
layout="wide",
)page_title
page_title=”ページタイトルの文字列“ でページタイトルが設定できます
ページタイトルとは、Webブラウザのタブに表示されるタイトルのことです。

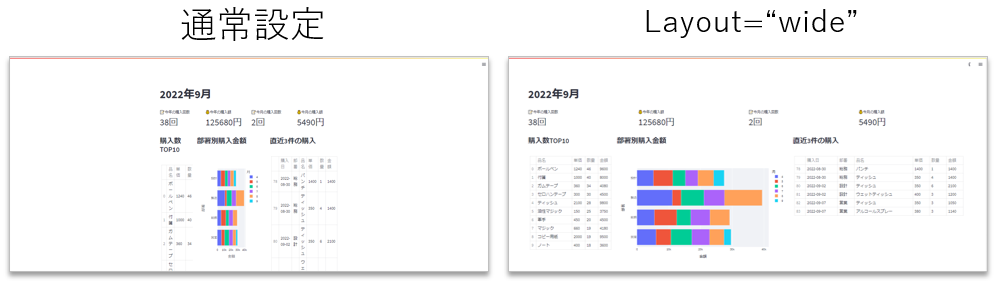
layout
layout=”wide“ とすると、ページの表示幅が広がります。
今回はグラフなどを横に並べたいので wide 設定にしておきます。
タイトル表示
まずはタイトルを表示させていきましょう。
今回は、現在の年月をタイトルとして表示させようと思います。
# 現在の年月を取得
today = date.today() # 今日の日付を取得
this_year = today.year # 年を取り出し
this_month = today.month # 月を取り出し
# タイトル表示
st.title(f"{this_year}年{this_month}月")現在の年月を取得
最初にインポートした dateライブラリを使って現在の日付を取得します。
下記のように date.today() で現在の日付が取得できます。
today = date.today().year で ”年”、.monthで ”月” が取り出せるので、それぞれを変数に入れておきます。
this_year = today.year
this_month = today.monthstreamlitでタイトル表示
取り出した現在の ”年月” を使ってタイトル表示をします。
streamlit の title() メソッドを使えば、引数で指定した文字列がタイトルに適した大き目の文字で表示されます。
st.title(f"{this_year}年{this_month}月")引数で渡す文字列は、f-string を使って”年月”の変数を埋め込んでいます。
これによって下記のように表示されます。

streamlit の起動方法
ここで、Streamlit で作ったWebアプリを起動させる方法をお伝えしておきます。
コマンドプロンプトで、streamlitのプログラムを書いたpythonファイルが置いてあるフォルダに移動してから、下記のコマンドを実行してください。
streamlit run streamlit_dashboard.py※ streamlit_dashboard.py の所はその時のファイル名にしてください。
成功すると下記のように表示されますので、表示されたURLをWebブラウザに打ち込めば作成したページが表示されます。

Streamlit 起動中は、プログラムを変更したら、Webブラウザの再読み込みをすれば変更が反映されます。
集計表示
# 4カラム表示
col1, col2, col3, col4 = st.columns(4)
# 今年の購入回数
this_year_counts = df.loc[df["購入日"].dt.year == this_year, "購入日|部署"].nunique()
col1.metric("📝今年の購入回数", f"{this_year_counts}回")
# 今年の購入額
this_year_purchase = df.loc[df["購入日"].dt.year == this_year, "金額"].sum()
col2.metric("💰今年の購入額", f"{this_year_purchase}円")
# 今月の購入回数
this_month_counts = df.loc[df["購入日"].dt.month == this_month, "購入日|部署"].nunique()
col3.metric("📝今月の購入回数", f"{this_month_counts}回")
# 今月の購入額
this_month_purchase = df.loc[df["購入日"].dt.month == this_month, "金額"].sum()
col4.metric("💰今月の購入額", f"{this_month_purchase}円")列レイアウト
Streamlit で複数列に分けて表示させるには st.columns() を使います
st.columns()の基本的な使い方
columns() の引数に、2列表示したいときは数字の2を、4列表示させたいときは数字の4を入れます。
指定した列数分の戻り値が返ってくるので変数で受けます。
あとは、〇番目の戻り値(変数)でstreamlitのメソッドを使うと〇列目に配置される、といった具合です。
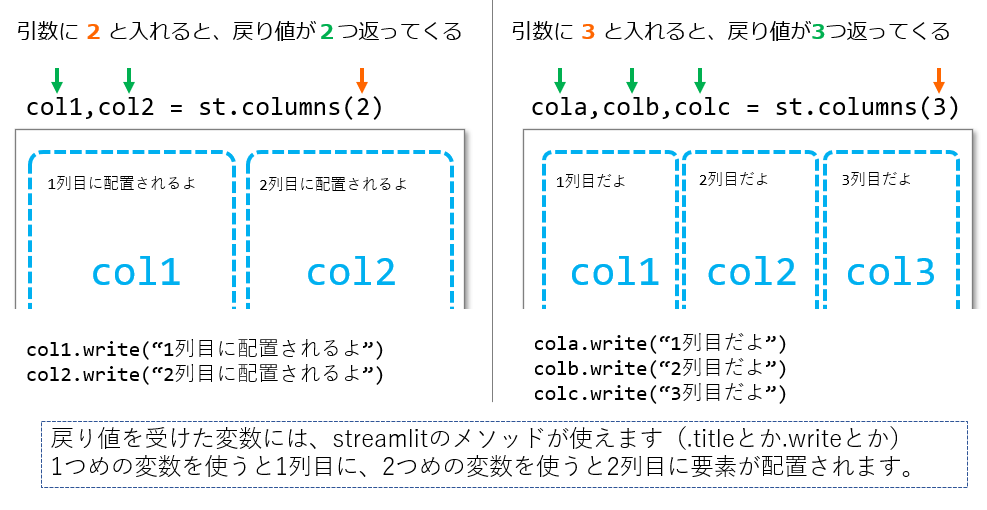
4列表示する
今回は4列で表示させたいので、下記のように書きます。
col1, col2, col3, col4 = st.columns(4)購入回数の集計
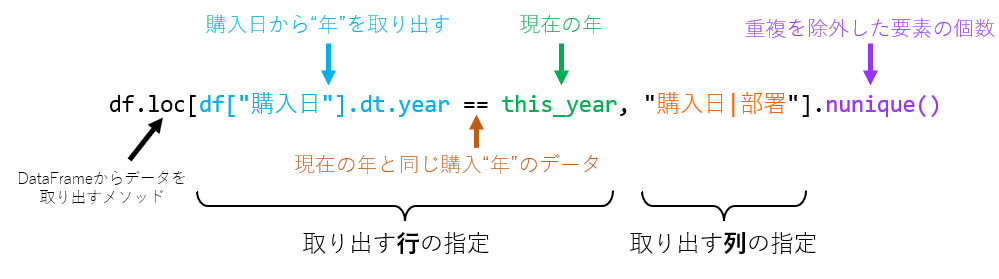
購入回数は下記の箇所で集計しています。
this_year_counts = df.loc[df["購入日"].dt.year == this_year, "購入日|部署"].nunique()
:
this_month_counts = df.loc[df["購入日"].dt.month == this_month, "購入日|部署"].nunique()これらのコードの意味は下記の通りです。
図は ”年” ですが、”月” もyearがmonthに変わるだけで基本は同じです。
購入金額の集計
購入金額は下記の箇所で集計しています。
this_year_purchase = df.loc[df["購入日"].dt.year == this_year, "金額"].sum()
:
this_month_purchase = df.loc[df["購入日"].dt.month == this_month, "金額"].sum()これらのコードの意味は下記の通りです。
先ほどの購入回数の集計とほとんど同じで
取り出す列が ”金額” 列に変わっているのと、合計を計算するように変わっているだけです。
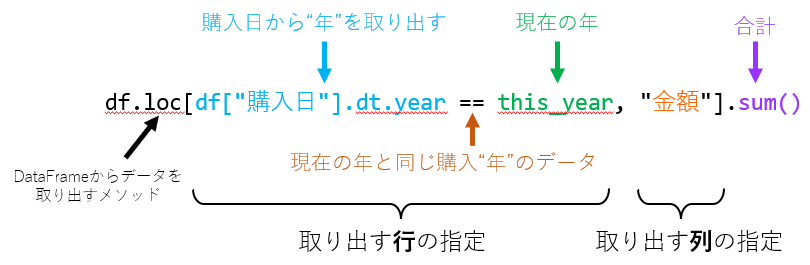
集計値の表示
下記の箇所で、集計した値を表示させています。
st.columns() で4列レイアウトにした、それぞれの列に配置しています。
col1.metric("📝今年の購入回数", f"{this_year_counts}回")
:
col2.metric("💰今年の購入額", f"{this_year_purchase}円")
:
col3.metric("📝今月の購入回数", f"{this_month_counts}回")
:
col4.metric("💰今月の購入額", f"{this_month_purchase}円")Windowsで絵文字を使うには
[Windows]キー + [.]キー を押すと一覧が表示されます。
前編のまとめ

ここまでで、下記のような表示をさせることができました。

まだ少し表示させただけですが、これでも立派なWebアプリです。
今回は、ExcelデータをPandasで読み込む方法と、Streamlit の基本的な使い方を説明しました。
次回の後編では、Plotlyを使ってインタラクティブなグラフを作成したりして、ダッシュボードを完成させます。
from datetime import date
import pandas as pd
import streamlit as st
import plotly.express as px
# エクセルの読み込み
df = pd.read_excel("./注文履歴.xlsx", sheet_name="Sheet1", header=0, usecols="A:G")
df = df.dropna() # 空白データがある行を除外
df[["単価", "数量", "金額"]] = df[["単価", "数量", "金額"]].astype(int) # 金額や数量を整数型に変換
# df["月"] = df["購入日"].apply(lambda x: str(x.month)) # "月"の列を追加
df["月"] = df["購入日"].dt.month.astype(str) # "月"の列を追加
df["購入日|部署"] = df["購入日"].astype(str).str.cat(df["部署"], sep="|") # "購入日|部署" 列を追加
# Streamlitのページ設定
st.set_page_config(
page_title="備品購入ダッシュボード",
layout="wide",
)
# 現在の年月を取得
today = date.today()
this_year = today.year
this_month = today.month
st.title(f"{this_year}年{this_month}月")
# 4カラム表示
col1, col2, col3, col4 = st.columns(4)
# 今年の購入回数
this_year_counts = df.loc[df["購入日"].dt.year == this_year, "購入日|部署"].nunique()
col1.metric("📝今年の購入回数", f"{this_year_counts}回")
# 今年の購入額
this_year_purchase = df.loc[df["購入日"].dt.year == this_year, "金額"].sum()
col2.metric("💰今年の購入額", f"{this_year_purchase}円")
# 今月の購入回数
this_month_counts = df.loc[df["購入日"].dt.month == this_month, "購入日|部署"].nunique()
col3.metric("📝今月の購入回数", f"{this_month_counts}回")
# 今月の購入額
this_month_purchase = df.loc[df["購入日"].dt.month == this_month, "金額"].sum()
col4.metric("💰今月の購入額", f"{this_month_purchase}円")
コメント