前回から引き続き、PythonのWebアプリ作成ライブラリ「Streamlit」を使って簡易的なダッシュボードを作っていきます。
>> 前回の記事はこちら

# 3カラム表示 (1:2:2)
col1, col2, col3 = st.columns([1, 2, 2])
# 購入数TOP10
many_df = df.groupby(by="品名").sum().sort_values(by="数量", ascending=False).reset_index()
col1.subheader("購入数TOP10")
col1.table(many_df[["品名", "単価", "数量", "金額"]].iloc[:10])
# 部署別購入金額
department_group_df = df.groupby(["部署", "月"]).sum()
fig = px.bar(department_group_df.reset_index(), x="金額", y="部署", color="月", orientation="h")
col2.subheader("部署別購入金額")
col2.plotly_chart(fig, use_container_width=True)
# 直近3件の購入
recent_df = df[df["購入日|部署"].isin(sorted(df["購入日|部署"].unique())[-3:])]
recent_df["購入日"] = recent_df["購入日"].dt.strftime("%Y-%m-%d")
col3.subheader("直近3件の購入")
col3.table(recent_df[view_columns])
# 月ごとの購入金額推移
month_group_df = df.groupby(["月", "部署"]).sum()
fig = px.bar(month_group_df.reset_index(), x="月", y="金額", color="部署", title="月別購入金額")
st.plotly_chart(fig, use_container_width=True)
# 詳細表示
with st.expander("詳細データ"):
# 表示する期間の入力
min_date = df["購入日"].min().date()
max_date = df["購入日"].max().date()
start_date, end_date = st.slider(
"表示する期間を入力",
min_value=min_date,
max_value=max_date,
value=(min_date, max_date),
format="YYYY/MM/DD")
col1, col2 = st.columns(2)
# 表示する部署の選択
departments = df["部署"].unique()
select_departments = col1.multiselect("表示部署", options=departments, default=departments)
df["購入日"] = df["購入日"].apply(lambda x: x.date())
detail_df = df[(start_date <= df["購入日"]) & (df["購入日"] <= end_date) & (df["部署"].isin(select_departments))]
productname_group_df = detail_df.groupby(["品名", "部署"]).sum()
view_h = len(productname_group_df)*15
fig = px.bar(productname_group_df.reset_index(), x="金額", y="品名", color="部署", orientation="h", title="購入品別購入金額", height=view_h+300, width=600)
fig.update_layout(yaxis={'categoryorder':'total ascending'})
col1.plotly_chart(fig, use_container_width=True)
col2.subheader("購入一覧")
col2.dataframe(detail_df[view_columns], height=view_h+200)この記事を見ながらプログラムを書いていかれる場合は
Streamlitを下記のコマンドで実行させて、ブラウザでアプリを表示させたまま
適宜ブラウザページの「更新」ボタンを押して、そこまで書いたプログラムを反映させて確認しながら進めてもらうと理解が早いと思います。
streamlit run streamlit_dashboard.py各種グループ分け集計
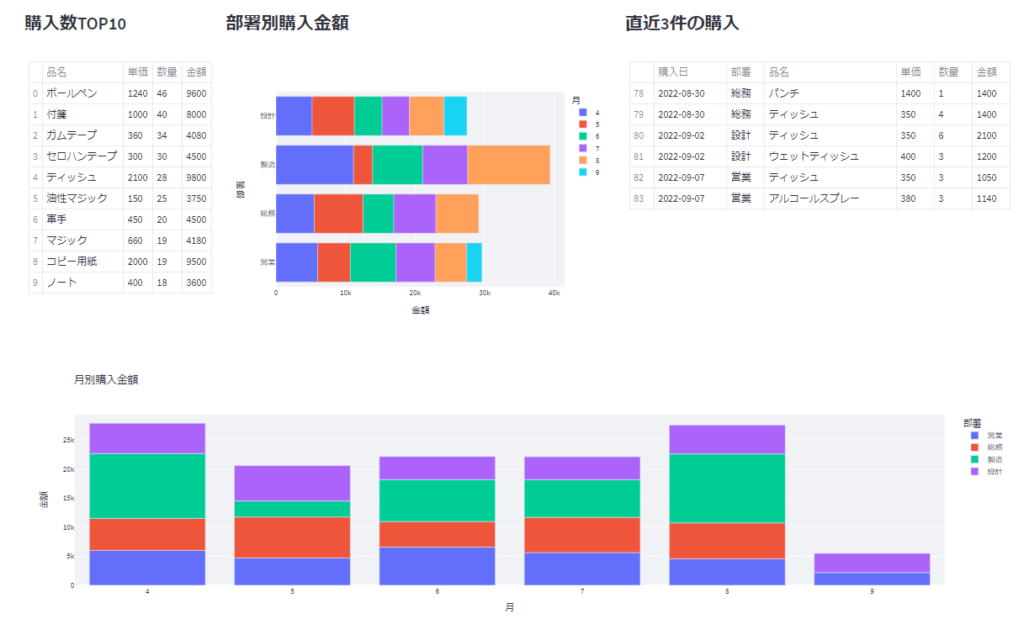
ここでは、色々な集計を行って表やグラフで表示させていきます。
# 3カラム表示 (1:2:2)
col1, col2, col3 = st.columns([1, 2, 2])
# 購入数TOP10
many_df = df.groupby(by="品名").sum().sort_values(by="数量", ascending=False).reset_index()
col1.subheader("購入数TOP10")
col1.table(many_df[["品名", "単価", "数量", "金額"]].iloc[:10])
# 部署別購入金額
department_group_df = df.groupby(["部署", "月"]).sum()
fig = px.bar(department_group_df.reset_index(), x="金額", y="部署", color="月", orientation="h")
col2.subheader("部署別購入金額")
col2.plotly_chart(fig, use_container_width=True)
# 直近3件の購入
recent_df = df[df["購入日|部署"].isin(sorted(df["購入日|部署"].unique())[-3:])]
recent_df["購入日"] = recent_df["購入日"].dt.strftime("%Y-%m-%d")
col3.subheader("直近3件の購入")
col3.table(recent_df[view_columns])
# 月ごとの購入金額推移
month_group_df = df.groupby(["月", "部署"]).sum()
fig = px.bar(month_group_df.reset_index(), x="月", y="金額", color="部署", title="月別購入金額")
st.plotly_chart(fig, use_container_width=True)不均等な列表示の設定
st.columns() は引数に整数のリストを渡すと、その整数の比率で列幅を設定できます。
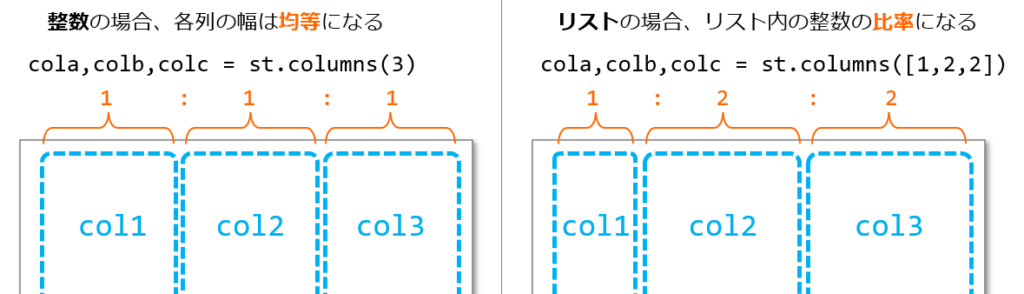
下記の箇所では、列幅を 1:2:2 で設定しています。
col1, col2, col3 = st.columns([1, 2, 2])購入数Top
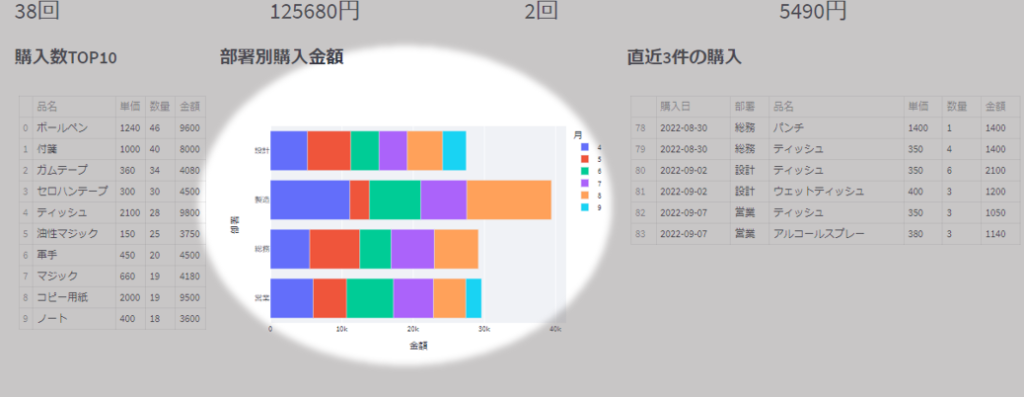
下図左側の「購入数Top10」の部分を作っていきます
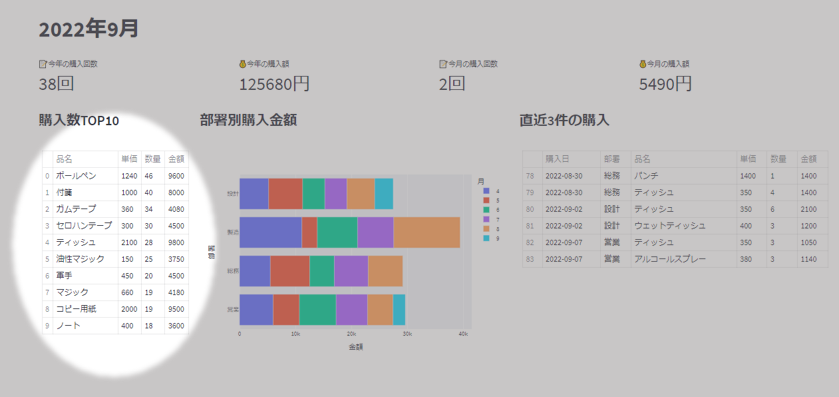
下記の行で、集計表を作成しています
many_df = df.groupby(by="品名").sum().sort_values(by="数量", ascending=False).reset_index()上記コードの処理内容を示したのが下図になります。
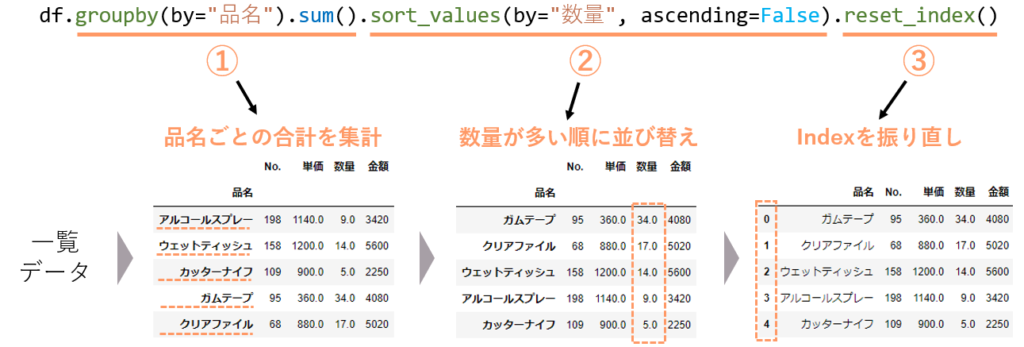
では、個々のメソッドを説明していきます。
groupby
Pandasのgroupbyは、指定した列が同じ値のデータをグループとして
そのグループごとに集計してくれるメソッドです。
例えば下記のように書くと「”品名“グループごとの合計」を集計してくれます
df.groupby(by="品名").sum()下記のように書くと「”部署“グループごとの平均」を集計してくれます
df.groupby(by="部署").mean()sort_values
sort_valuesは、データをソート(整列)してくれるメソッドです。
下記のように書くと、”数量”列の値でソートしてくれます
データフレームオブジェクト.sort_values(by="数量", ascending=False)ascending引数は、Trueだと値の小さいものが上に、Falseだと値の大きいものが上に整列します。
reset_index
一番後ろに付けている reset_index はデータフレームのインデックスを振り直すメソッドです。
groupbyで返ってきた集計されたデータフレームは、グループ分けに指定した列がインデックスになっています。
このままだと扱いにくいので、reset_indexをすることで通常の連番インデックスの形になります。
集計表の表示
下記の部分で、streamlitを使って集計した表を表示させています。
col1.subheader("購入数TOP10")
col1.table(many_df[["品名", "単価", "数量", "金額"]].iloc[:10])subheader()
サブ見出しの大きさの文字列を表示させるメソッドです
table()
Pandasのデータフレームを表示してくれます。
上記では、df.iloc[:10] とすることで上から10行だけを取り出して渡しています。
streamlitにはtable()の他に、dataframe()メソッドでもデータフレームを表示できます
今回は、静的な表を表示させたかったのでtable()を使いました。
部署別購入金額
次に「部署別購入金額」の部分を作っていきます。
グラフのための集計
下記の部分でグラフに使用する集計表を、groupbyを使って作成しています。
department_group_df = df.groupby(["部署", "月"]).sum()groupbyは上記のように、リストを使って複数の列を指定すると
指定した列の組み合わせでグループ分けをして集計してくれます。
plotlyでグラフ作成
下記の箇所は、plotly.expressを使って棒グラフを作っています
fig = px.bar(department_group_df.reset_index(), x="金額", y="部署", color="月", orientation="h")px.bar()
棒グラフを作成するメソッド
- 第一引数:グラフ化したいデータフレームを渡す
- x:グラフの横軸に使う列を指定
- y:グラフの縦軸に使う列を指定
- color:色分けに使用する列を指定
- orientation:グラフの方向指定(”v”=縦、”h”=横)
作成したグラフの表示
下記の部分は、上で作成したグラフをstreamlitで表示させています
col2.subheader("部署別購入金額")
col2.plotly_chart(fig, use_container_width=True)plotly_chart()
plotlyで作成したグラフを表示させるメソッドです
第一引数に、px.bar()で作成したグラフオブジェクトを渡します
use_container_width=True とすると、列の幅に合わせてグラフの大きさが調整されて表示されます。
直近〇件の購入
次は「直近〇件の購入」部分です
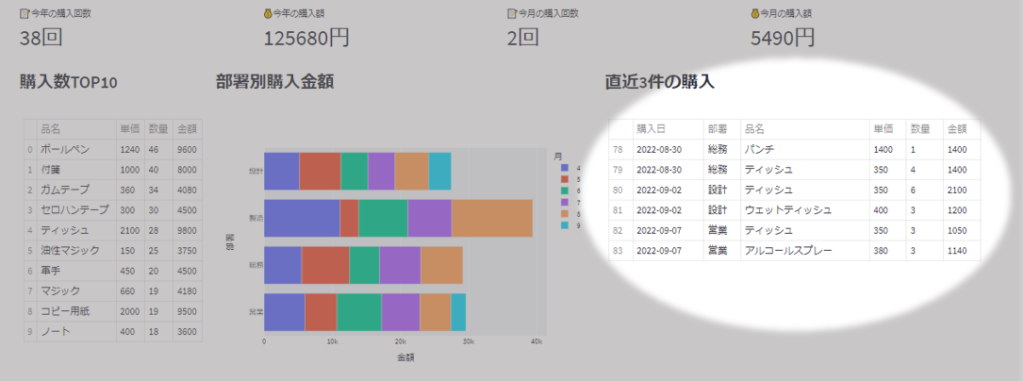
直近3件の抽出
今回は、1回の手配を1件とカウントしたいと思います
ここでは、同一部署が同一日に注文したものは全て同じ手配(つまり1件)として扱うことにします。
recent_df = df[df["購入日|部署"].isin(sorted(df["購入日|部署"].unique())[-3:])]
※上図の丸番号と、下記リストの番号が対応しています。
- unique()
- uniqueは重複を無くした一覧を取得するメソッドです
- ここでは ”購入日|部署” 列のデータの種類一覧を取り出しています
- sorted()
- sortedはデータを昇順(または降順)に並べ替える関数です。
- ①のuniqueで取り出した ”購入日|部署” のデータに対して実行することで、購入日順に並んだデータを得ることができます(先頭が日付が古いデータ)
- [-3:]
- [-3:]の部分で、リストの後ろから3番目以降のデータを取り出しています
- sortedで並び替えているので、日付の新しいものから3つの ”購入日|部署” データが取り出されます。
- isin()
- isinは、引数に指定した配列の
日付データを文字列に変換
PandasでExcelファイルを読込んだ時に、日付を表すデータは自動で日付型に変換されます。
このままstreamlitで表示させると、下記のようになりちょっと見づらいです。
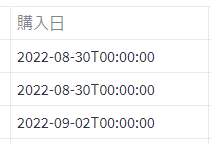
そこで、日付型から文字列型に変換してやります。
recent_df["購入日"] = recent_df["購入日"].dt.strftime("%Y-%m-%d").dt.strftime()
Pandasの日付型データは、.dt.strftime()というメソッドを使って
フォーマットを指定しながら文字列型に変換することができます。
引数で、変換したいフォーマットを指定します。
日付のフォーマット
日付型を文字列に変換するときによく使うフォーマットは下表のとおりです。
| %Y | 年(4桁) |
| %y | 年(2桁) |
| %m | 月(2桁) |
| %d | 日(2桁) |
| %H | 時(2桁、24時間表記) |
| %M | 分(2桁) |
| %S | 秒(2桁) |
例えば今回の例だと下記のようになります
(フォーマット)%Y–%m–%d ➡ (変換後文字列)”2022–08–30“
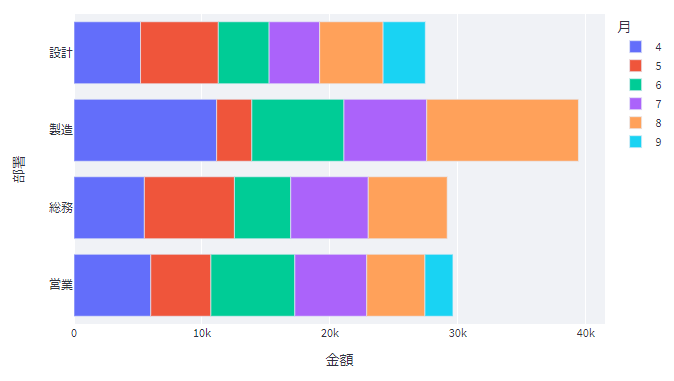
月別購入金額
次は「月別購入金額」の箇所です
これは、月ごとの各部署の購入金額を棒グラフで表したものです。
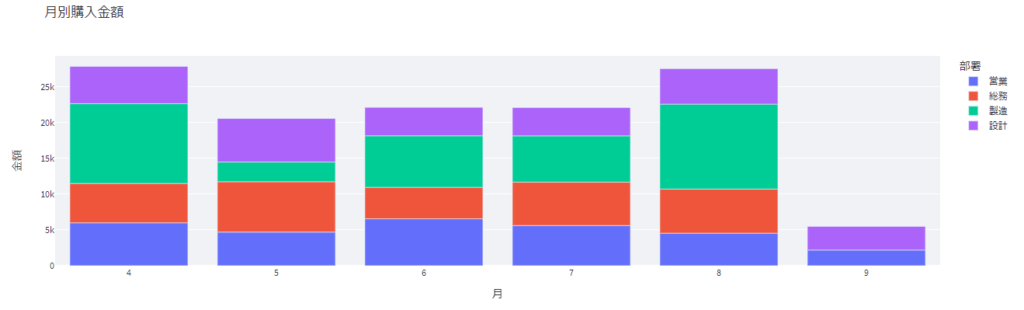
ここは、これまで説明した方法を使っているだけなので説明は省略します。
month_group_df = df.groupby(["月", "部署"]).sum()
fig = px.bar(month_group_df.reset_index(), x="月", y="金額", color="部署", title="月別購入金額")
st.plotly_chart(fig, use_container_width=True)一点だけ、plotly express の棒グラフ px.bar() のところは少し変えていますので補足しておくと
ここでは縦向きの棒グラフを表示させたいので、引数 orientation=”h” は削除しています
(縦向きグラフを表す “v” はデフォルトなので指示する必要無し)
あと表題を表示させたかったので title=”月別購入金額” という引数を追加しています。
インタラクティブな詳細データ表示
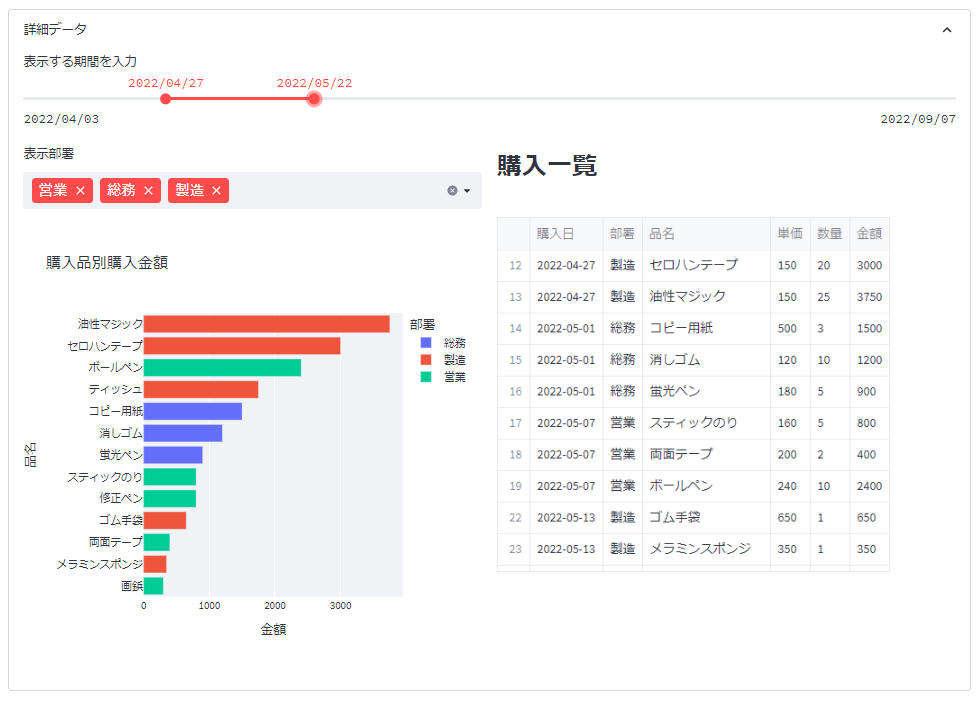
ここで作りたいのは
表示させたい「期間」と「部署」を選択すると、その場でグラフと一覧表の表示が切り替わる
というものです
そこで必要となる、streamlitでの入力ウィジェットの使い方を中心に説明していきます
表示期間の指定(スライダー)
streamlitには色々な入力ウィジェットが用意されていますが
ここでは範囲を選択するのに適した「スライダー」というウィジェットを使います

選択可能範囲(上限下限)の設定
まず選択可能な範囲を設定します。
今回は、購入日 の範囲を指定するようにしたいので
Excelから読込んだデータの ”購入日” 列から、一番古い日と一番新しい日を取得すれば良さそうです。
min_date = df["購入日"].min().date()
max_date = df["購入日"].max().date()そこで下記のように、min()とmax()を使って”購入日”列の最小(古い)値と最大(新しい)値を取り出します。
そのままだと時間情報も含んだTimestamp型で返ってくるので、date()で日付だけのデータに変換しておきます。
slider()
ではstreamlitの slider() を使ってスライダーウィジェットを配置します
start_date, end_date = st.slider(
"表示する期間を入力",
min_value=min_date,
max_value=max_date,
value=(min_date, max_date),
format="YYYY/MM/DD"
)引数
- 第一引数:表示ラベルの文字列
- min_value:選択可能範囲の最小値
- max_value:選択可能範囲の最大値
- value:初期の値
- 1つの値を設定すると、1つの値を選択するスライダーになる
- 2つの値のリスト(orタプル)を設定すると、範囲を選択するスライダーになる
- format:値の表示フォーマットを指定
※上で説明した日付フォーマットと表記が異なるので注意!
入力された値
入力(選択)された値は、戻り値で返ってきますので変数で受け取ります。
スライダーの場合、1つの値選択スライダーの場合は1つの値、範囲選択スライダーの場合は2つの値が返ってきます。
- 1つの値選択スライダー
- value = st.slider( 引数 )
- 範囲選択スライダー
- min_value, max_value = st.slider( 引数 )
表示部署の選択(マルチセレクト)
次に表示させる部署を選択するウィジェットを作っていきます
一度に複数の部署を選択できるようにしたいので「マルチセレクト」を使います。

部署名の一覧を取得
選択肢となる部署名の一覧は、上で説明したunique()メソッドを使って抽出します。
departments = df["部署"].unique()multiselect()
streamlitで複数選択用のウィジェットとして multiselect() が用意されています。
select_departments = col1.multiselect("表示部署", options=departments, default=departments)引数
- 第一引数:表示ラベルの文字列
- options:選択肢の配列(リストやNumpy.arrayなど)
- default:初期の選択リスト(単一選択させたい場合は単一の値でもOK)
引数の optinas と default には、先ほど抽出した部署名一覧を渡します。
入力された値
選択された値は戻り値で返ってきますので、ここではselect_departmentsという変数で受け取っています。
multiselect の戻り値は、選択された値が格納されたリストになります。
※1つも選択されていない場合は、空のリストが返ります。
入力値に合致するデータを抽出
入力ウィジェットで入力された値を使い、それに合致するデータだけを抽出し
そのデータを使ってグラフなどを表示させることでインタラクティブな表示が実現できます。
購入日列をdate型に変換
入力ウィジェットで入力された購入日範囲のデータはdate型
それに対してDataFrameの “購入日” 列はdatetime型で
そのままでは比較ができないので、”購入日”列のほうをdate型に変換します。
df["購入日"] = df["購入日"].apply(lambda x: x.date())DataFrameの列ごとデータ型を変換したいところですが、あいにくDataFrameの列にdate型は用意されていません。
そこで、apply() を使って中のデータ一つ一つに対して型変換をしていきます。
apply()
Pandas.Seriesのメソッドであるapply()は、中のデータ一つ一つに対して指定した関数を実行することができます。
引数に、適用させたい関数を指定します。
df["購入日"].apply(lambda x: x.date())しかし、ここで引数に指定している関数は見慣れない表記になっていると思う人もおられるかもしれません。
これはラムダ式や無名関数と呼ばれるれっきとした関数なのですが、知らないと何をしているのか分かりにくいと思いますので以下で簡単に説明します。
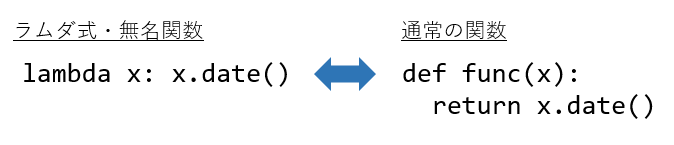
lambda(ラムダ式・無名関数)
lambda(ラムダ式・無名関数)は、通常のdefを使った関数より簡潔に記述することができる関数の書き方です。
基本的に、今回のapply()など、何らかの他のメソッドと組み合わせて使うことが多いです。
lambdaの書き方
lamdaの基本的な書き方は下記のようになります
lambda 引数: 引数に対する処理今回 apply() の引数で渡している ラムダ式 の部分だけ抜き出すと下記のようになります。
lambda x: x.date()この意味は、xという引数(引数の名前はなんでも良い)に対して.date()メソッドを実行する、となります。
より理解しやすいように、lamda と 通常の関数 の書き方を比較したものを載せておきます。
DataFrameでデータ抽出
では “購入日” 列を条件式に使える型に変換したところで
DataFrameの条件式を使ったデータ抽出で、入力された条件に合致するデータだけを抽出します。
detail_df = df[(start_date <= df["購入日"]) & (df["購入日"] <= end_date) & (df["部署"].isin(select_departments))]購入品別の購入金額グラフ
入力値によって抽出したDataFrameを使って「購入品別の購入金額」のグラフを作成します。
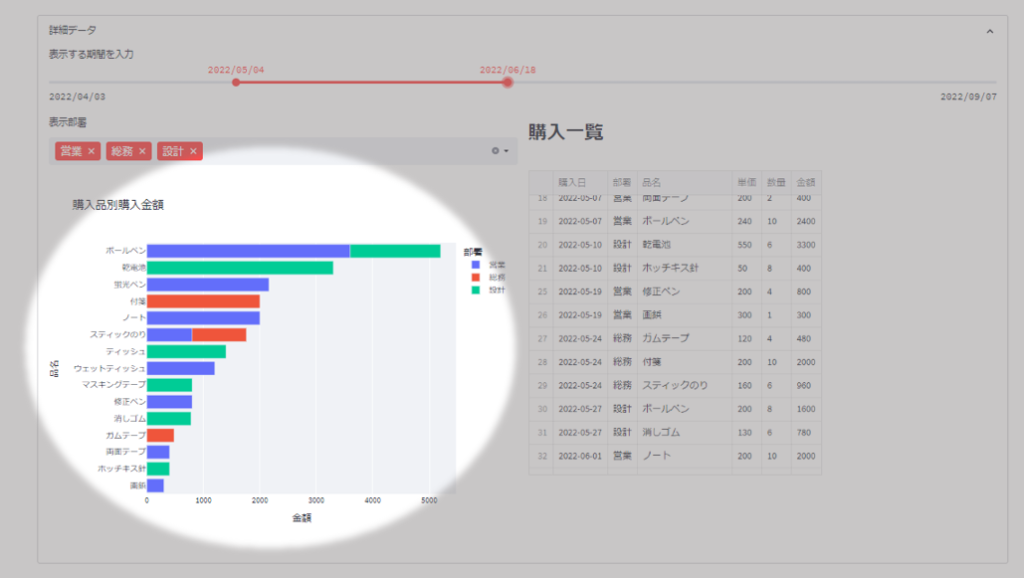
コードは下記のようになります。
productname_group_df = detail_df.groupby(["品名", "部署"]).sum()
view_h = len(productname_group_df)*15
fig = px.bar(productname_group_df.reset_index(), x="金額", y="品名", color="部署", orientation="h", title="購入品別購入金額", height=view_h+300, width=600)
fig.update_layout(yaxis={'categoryorder':'total ascending'})
col1.plotly_chart(fig, use_container_width=True)基本的にはここまでで説明してきた方法を使えば良いのですが、一部新たな要素が出てきていますのでその部分だけ説明します。
棒グラフの表示サイズ指定
plotlyのグラフサイズが、思うように自動調整されなかったので、サイズ指示をしています。
もしかしたら、良い感じに自動調整させる方法が存在するかもしれません
ご存じの方、発見された方は教えていただけると嬉しいです。
下記1行目で、抽出したデータの数によって縦サイズが変わるように定義しています
そして2行目の px.bar()の引数にその値を渡してグラフサイズを指定しています
view_h = len(productname_group_df)*15
fig = px.bar( ・・・ , height=view_h+300, width=600)グラフを値の大きい順に表示
下記の箇所で、plotlyの棒グラフを値の大きい順に表示されるようにしています。
fig.update_layout(yaxis={'categoryorder':'total ascending'})購入一覧表
次は、入力値によって抽出したDataFrameを使って「購入一覧」表を作ります。
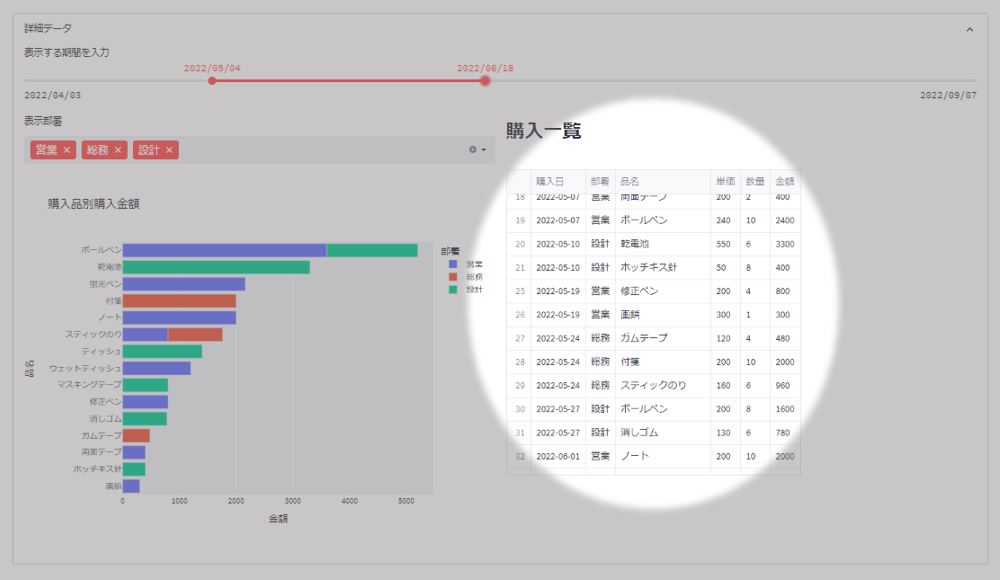
この部分は、ここまでで説明した内容で分かると思いますので説明は省きます。
col2.subheader("購入一覧")
col2.dataframe(detail_df[view_columns], height=view_h+200)アコーディオンメニュー化
最後に、これらインタラクティブな表示要素を、折り畳み可能な「アコーディオンメニュー」にします。
streamlitでアコーディオンメニューにするには、expander() を使います.
使い方は、下記のように Python の with文 を使い下記のように書きます。
with st.expander(ラベルの文字列):
アコーディオンメニューの中に入れる表示や処理
:従って、今回は購入日の範囲入力の所から下を全て中に入れたいので
下記のようになります。
with st.expander("詳細データ"):
min_date = df["購入日"].min().date()
max_date = df["購入日"].max().date()
:
col2.subheader("購入一覧")
col2.dataframe(detail_df[view_columns], height=view_h+200)これで、折りたたんで 表示・非表示を切り替えられるようになりました。
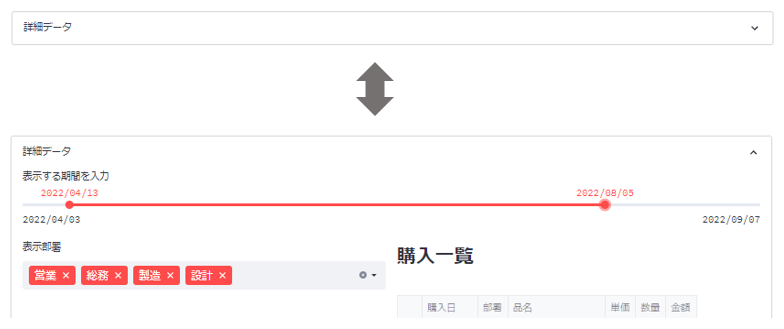
完成🎊

これでようやくダッシュボードが完成しました🎉
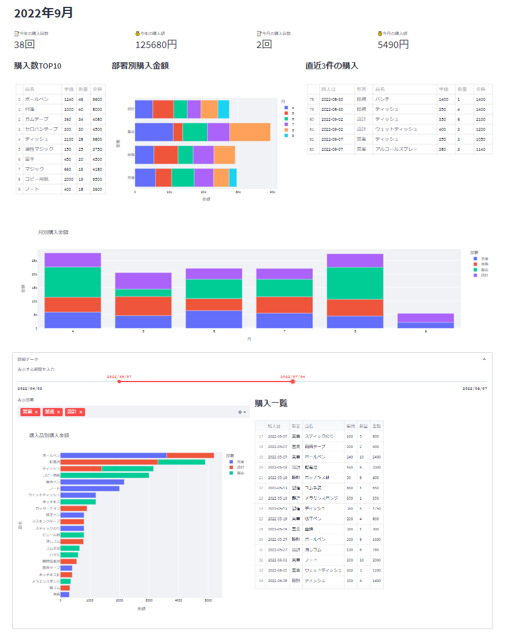
最後に、前回(前編)と今回(後編)を合わせた全コードを載せておきます。
from datetime import date
import pandas as pd
import streamlit as st
import plotly.express as px
# エクセルの読み込み
df = pd.read_excel("./注文履歴.xlsx", sheet_name="Sheet1", header=0, usecols="A:G")
df = df.dropna() # 空白データがある行を除外
df[["単価", "数量", "金額"]] = df[["単価", "数量", "金額"]].astype(int) # 金額や数量を整数型に変換
df["月"] = df["購入日"].dt.month.astype(str) # "月"の列を追加
df["購入日|部署"] = df["購入日"].astype(str).str.cat(df["部署"], sep="|") # "購入日|部署" 列を追加
view_columns = ['購入日', '部署', '品名', '単価', '数量', '金額']
# Streamlitのページ設定
st.set_page_config(
page_title="備品購入ダッシュボード",
layout="wide",
)
# 現在の年月を取得
today = date.today()
this_year = today.year
this_month = today.month
this_year = 2022 # サンプルCSVをそのまま使用する場合はこの行のコメントを解除してください
this_month = 9 # サンプルCSVをそのまま使用する場合はこの行のコメントを解除してください
st.title(f"{this_year}年{this_month}月")
# 4カラム表示
col1, col2, col3, col4 = st.columns(4)
# 今年の購入回数
this_year_counts = df.loc[df["購入日"].dt.year == this_year, "購入日|部署"].nunique()
col1.metric("📝今年の購入回数", f"{this_year_counts}回")
# 今年の購入額
this_year_purchase = df.loc[df["購入日"].dt.year == this_year, "金額"].sum()
col2.metric("💰今年の購入額", f"{this_year_purchase}円")
# 今月の購入回数
this_month_counts = df.loc[df["購入日"].dt.month == this_month, "購入日|部署"].nunique()
col3.metric("📝今月の購入回数", f"{this_month_counts}回")
# 今月の購入額
this_month_purchase = df.loc[df["購入日"].dt.month == this_month, "金額"].sum()
col4.metric("💰今月の購入額", f"{this_month_purchase}円")
# 3カラム表示 (1:2:2)
col1, col2, col3 = st.columns([1, 2, 2])
# 購入数TOP10
many_df = df.groupby(by="品名").sum().sort_values(by="数量", ascending=False).reset_index()
col1.subheader("購入数TOP10")
col1.table(many_df[["品名", "単価", "数量", "金額"]].iloc[:10])
# 部署別購入金額
department_group_df = df.groupby(["部署", "月"]).sum()
fig = px.bar(department_group_df.reset_index(), x="金額", y="部署", color="月", orientation="h")
col2.subheader("部署別購入金額")
col2.plotly_chart(fig, use_container_width=True)
# 直近3件の購入
recent_df = df[df["購入日|部署"].isin(sorted(df["購入日|部署"].unique())[-3:])]
recent_df["購入日"] = recent_df["購入日"].dt.strftime("%Y-%m-%d")
col3.subheader("直近3件の購入")
col3.table(recent_df[view_columns])
# 月ごとの購入金額推移
month_group_df = df.groupby(["月", "部署"]).sum()
fig = px.bar(month_group_df.reset_index(), x="月", y="金額", color="部署", title="月別購入金額")
st.plotly_chart(fig, use_container_width=True)
# 詳細表示
with st.expander("詳細データ"):
# 表示する期間の入力
min_date = df["購入日"].min().date()
max_date = df["購入日"].max().date()
start_date, end_date = st.slider(
"表示する期間を入力",
min_value=min_date,
max_value=max_date,
value=(min_date, max_date),
format="YYYY/MM/DD")
col1, col2 = st.columns(2)
# 表示する部署の選択
departments = df["部署"].unique()
select_departments = col1.multiselect("表示部署", options=departments, default=departments)
df["購入日"] = df["購入日"].apply(lambda x: x.date())
detail_df = df[(start_date <= df["購入日"]) & (df["購入日"] <= end_date) & (df["部署"].isin(select_departments))]
productname_group_df = detail_df.groupby(["品名", "部署"]).sum()
view_h = len(productname_group_df)*15
fig = px.bar(productname_group_df.reset_index(), x="金額", y="品名", color="部署", orientation="h", title="購入品別購入金額", height=view_h+300, width=600)
fig.update_layout(yaxis={'categoryorder':'total ascending'})
col1.plotly_chart(fig, use_container_width=True)
col2.subheader("購入一覧")
col2.dataframe(detail_df[view_columns], height=view_h+200)まとめ
長くなってしまいましたが、最後までご覧いただきありがとうございます。
Python初心者の方には、Streamlit・Pandas・Plotly など色々なライブラリが出てきて難しかったと思いますが
一度、この記事通りにプログラムを書いてダッシュボードを作っていただいた後で
今回のプログラムを元に、ぜひご自身のまわりのExcelデータを使ってダッシュボード作成をしていただけたらと思います。
コメント