
業務でエクセルを使用することは多いと思いますが
「エクセルから必要なデータだけを取ってくる」
「大量のエクセルに同じ処理をしなければならない」
このような作業を面倒に感じている人もおられるのではないでしょうか?
こんな面倒な作業も、Pythonを使えば、ミスなく 一瞬で処理することが可能です!
しかも、意外と簡単な短いプログラムで実装することができます。
今回は、ひとつずつ処理を説明しながら、段階的に作っていきますので
Python初心者の人でも理解していただけると思います。
- エクセルの転記作業などを自動化したい人
- 複数のエクセルファイルを一括で処理したい人
- Python初心者の人
Pythonを使って
- エクセルからデータを抽出してくる方法が分かります
- フォルダ内の複数のファイルに対して処理をする方法が分かります
- データを集計して出力する方法が分かります

概要

想定する場面
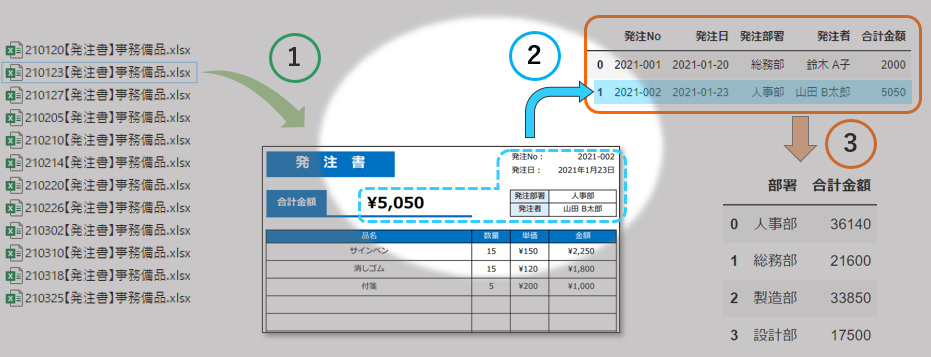
下図のようなイメージで
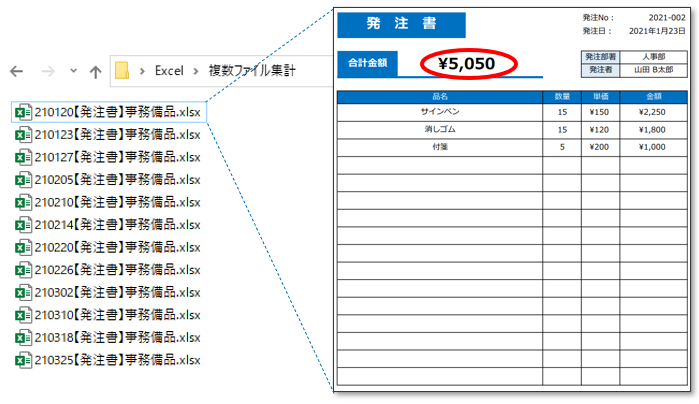
- フォルダ内に複数のエクセルがある
- 各エクセルは同じ書式(この例では発注書)
- 全てのエクセルから所定の箇所のデータを抽出したい(この例では合計金額とその他項目)
というような場面を想定して説明していきたいと思います。
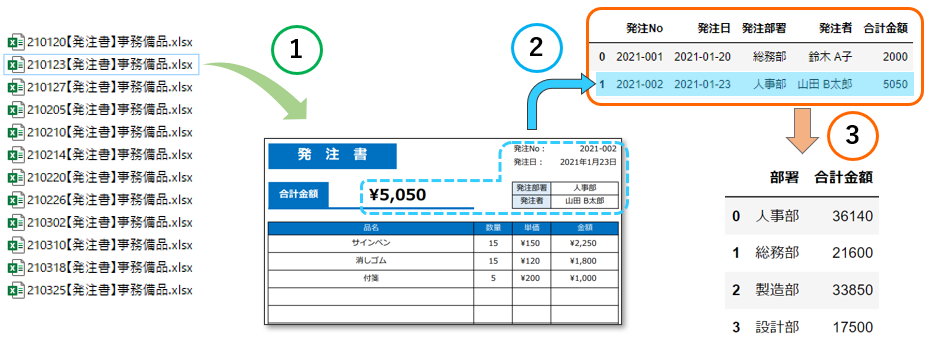
大まかな流れ
- フォルダからエクセルファイルだけを見つけ出して読み込む
- エクセルから必要なデータを取得する
- 集めたデータを集計する
前準備
使用するライブラリ
今回は以下のライブラリを使用します。
- glob 標準ライブラリ … フォルダから必要なファイルを取得するのに使用
- openpyxl 外部ライブラリ … エクセルファイルを操作するのに使用
- pandas 外部ライブラリ … データ集計に使用
外部ライブラリのインストール
使用する外部ライブラリの、pipでのインストール方法も載せておきます。
インストールがまだの方は、下記コマンドでインストールをしてください。
pip install openpyxl
pip install pandasライブラリについての詳しい説明は下記の記事をご覧ください。

使用するエクセルファイル
業務での具体的な使用場面をイメージしやすいように、下図のようなエクセルを用意しました
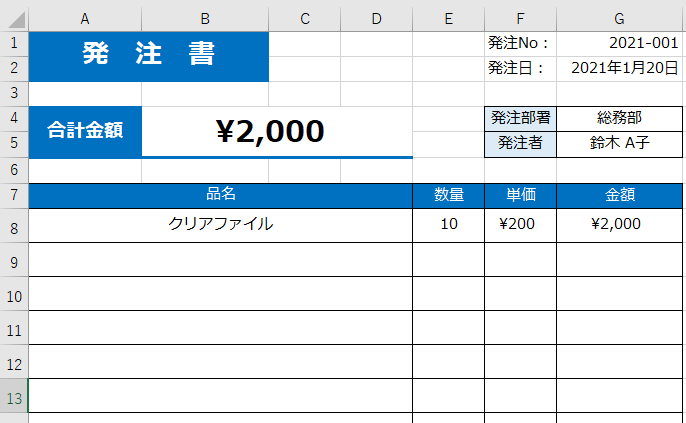
「発注書」をイメージして作っています。
この記事では上記のエクセルをもとに説明をしていきますが
必要に応じて、ご自身のエクセルに置き換えてみていただければと思います。
基本の処理
それでは、Pythonを使ってプログラムを書いていきます。
まずは、それぞれの処理ごとにパートを分けて説明していきます。
Pythonファイルの新規作成(Jupyter notebook)
今回は、Jupyter notebook (ジュピターノートブック) を使って実装していきます。
今回は、分かりやすいように
エクセルと同じフォルダに Jupyter notebook のファイルを作ります
画像では python_excel_sample.ipynb というファイル名にしていますが自由に付けてもらって構いません。
Jupyter notebook 起動
コマンドプロンプトに下記を打ち Jupyter notebook を起動します
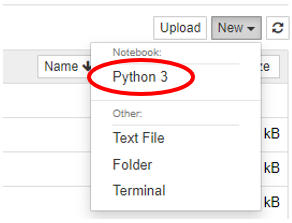
jupyter notebookファイルの新規作成
[New] から Python3 の Notebook を新規作成します。
エクセルからデータを抽出する
Pythonを使ってエクセルからデータを抽出する方法を説明します。
先ほどの全体図の ② の前半部分に当たります。
openpyxl のインポート
エクセルファイルの読み込みにopenpyxlというライブラリを使用するため、最初にインポートします。
import openpyxlOpenpyxl でエクセルの ”ブック” を開く
まずプログラム上でエクセルのブックを開きます
openpyxl でエクセルのブックを開くには openpyxl.load_workbook() を使用します
load_workbook() の引数には、開きたいエクセルのパスを指定します。
# エクセルファイルのパス
file_path = "./210120【発注書】事務備品.xlsx"
# ワークブックを開く
wb = openpyxl.load_workbook(file_path, data_only=True)加えて今回は data_only=True という引数を指定しています
この引数は、今回のように関数を使用したエクセルから、関数で計算された値を取得したい場合に True を指定します。

エクセルの ”シート” を取得
開いたブックから シート を取得します
シートは、先ほど開いたブックオブジェクト(wb)に
ブックオブジェクト["シート名"]
で取得することができます。
# "発注書" シートを取得
sheet = wb["発注書"]エクセルの ”セル” の値を取得
シートオブジェクトから、セル の値を取得するには下記のように書きます
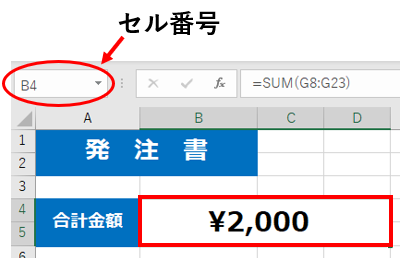
シートオブジェクト["セル番号"].value
セル番号は画像の赤丸箇所を見れば分かります
今回のエクセルの「合計金額」の値を取得したい場合は、セル番号が “B4” なので
プログラムにすると下記のようになります。
# 「合計金額」の値を取得
value = sheet["B4"].value
print(value) # 取得した値を表示
# > 2000Pandasのデータフレームに抽出したデータを追加する
エクセルから抽出したデータは、集計したり扱いやすいように Pandasのデータフレーム形式 に変換したいと思います。
先ほどの全体図の ② の後半部分に当たります。

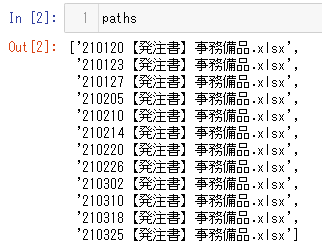
下図のように、[発注No、発注日、発注部署、発注者、合計金額] のデータを扱うこととします。

空のデータフレームを作成する
今回は、エクセルから取得したデータを1行ずつデータフレームに追加していきたいので
まず何もデータが入っていない空のデータフレームを作成します。
この時、各データが入るカラム名(列名)はあらかじめ設定しておきます
カラム名(列名)を指定しつつ空のデータフレームを作成するには下記のように書きます。
df = pd.DataFrame(columns=["発注No", "発注日", "発注部署", "発注者", "合計金額"])引数 columns にカラム名(列名)をリスト形式で渡すことでカラムを設定できます。
これによって作られたデータフレームは下図のような、カラム名(列名)だけが設定されていて、中身は何も入っていないものになります。

データフレームに追加するデータを作成
データフレームに行を追加する方法はいくつかありますが、今回は一旦辞書型データにエクセルから抽出してきた値を入れていき、一行分溜まったらデータフレームに変換して追加用行データを作り、それをメインのデータフレームへ追加するようにします
データ追加の流れ
- 空の辞書を用意(1行分のデータになる)
- エクセルから一つずつ値を抽出して辞書に入れていく
- 辞書に1行分のデータが溜まったらデータフレームに変換
- 変換した1行分のデータフレームをメインのデータフレームに連結
辞書データの作成
行追加のために作成する辞書データは下記の例のようになります。
この時、 keyにカラム名、valueにそのカラムのデータ とします。
変数 = {"発注No": "2021-001",
"発注日": "2021-01-21",
"発注部署": "総務部",
"発注者": "伊藤 K子",
"合計金額": 6000}下記のように書くことで、辞書にデータを追加することができます。
辞書変数["key"] = value
辞書データをデータフレームに変換する
辞書に1行分のデータが溜まったら、データフレームに変換します。
辞書をデータフレームへ変換するには、pd.DataFrame() を使います。
add_df = pd.DataFrame([辞書の変数])この時、データが1行分しか無い場合は辞書をリストに入れて( []で囲って )渡します。
なぜ、1行分の辞書データの場合はリストに入れて渡すのかと言うと
本来、辞書データをデータフレームに変換する場合は下記のような、リストに複数の辞書が入ったものを変換するように想定されています
[ {“発注No”: “2021-001”, “発注日”: “2021-01-21”, ~ },
{“発注No”: “2021-002”, “発注日”: “2021-01-27”, ~ },
:
{“発注No”: “2022-023”, “発注日”: “2022-04-13”, ~ } ]
1行だけの場合も、このような構造のデータにするためにリストに入れるというわけです。
メインデータフレームに行データフレームを追加(連結)する
メインデータフレームに行データフレームを追加(連結)するには、pd.concat() メソッドを使用します。
pd.concat([メインデータフレーム, 追加する行の辞書型], axis=0, ignore_index=True)
- axis : 連結の向き(0=縦、1=横)
- ignore_index : インデックスの振り直しの有無(True=有、False=無)
df = pd.concat([df, add_df], axis=0, ignore_index=True)この時、ignore_index=True とするのを忘れないようにしてください。
フォルダ内のエクセルだけを読み込む
フォルダ内のエクセルファイルだけを読み込むのに globモジュールのglob関数を使用します。
先ほどの全体図の ① の部分に当たります。
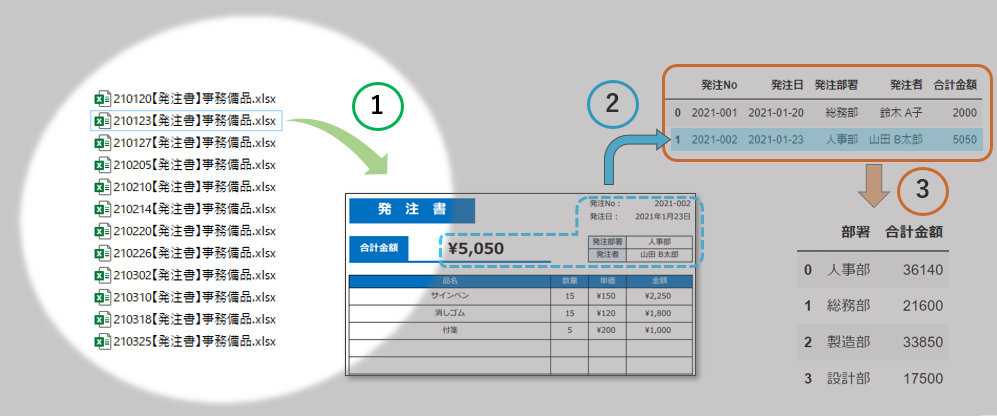
glob関数は指定したパターンにマッチするパスをリスト形式で返します。
下記のように書くと、フォルダ内のエクセルファイル(拡張子が.xlsx)のファイルパスをリストで返してくれます。
import glob
path_str = "*.xlsx"
paths = glob.glob(path_str)glob関数からの返り値を受け取った paths変数の中身を表示させてみると
下記のようにフォルダ内のエクセルファイルのパス一覧が格納されているのが分かります。
プログラムを完成させる
ここまでで説明した個々の処理を組み合わせてプログラムを完成させます。
個々の処理を組合わせて仕上げる
処理を組み合わせて仕上げたプログラムが下記になります
# ライブラリのインポート
import glob
import openpyxl
import pandas as pd
# 空のデータフレームを作成
df = pd.DataFrame(columns=["発注No", "発注日", "発注部署", "発注者", "合計金額"])
# ファイルパスのリスト取得
path_str = "*.xlsx"
paths = glob.glob(path_str)
for file_path in paths: # file_path変数にファイルパスが1つずつ入る
# 空の辞書を作成
wb_data = {}
# ブックを開く
wb = openpyxl.load_workbook(file_path, data_only=True)
# 発注書シートを取得
sheet = wb["発注書"]
# 「発注NO」
value = sheet["G1"].value # G1セルの値取得
wb_data["発注No"] = value # 行辞書に追加
# 「発注日」
value = sheet["G2"].value # G2セルの値取得
wb_data["発注日"] = value # 行辞書に追加
# 「発注部署」
value = sheet["G4"].value # G4セルの値取得
wb_data["発注部署"] = value # 行辞書に追加
# 「発注者」
value = sheet["G5"].value # G5セルの値取得
wb_data["発注者"] = value # 行辞書に追加
# 「合計金額」
value = sheet["B4"].value # B4セルの値取得
wb_data["合計金額"] = value # 行辞書に追加
# 辞書をデータフレームに変換
add_df = pd.DataFrame([wb_data])
# データフレームに行を追加
df = pd.concat([df, add_df], axis=0, ignore_index=True)
# ブックオブジェクトを閉じる
wb.close()glob関数で取得したエクセルファイルパスのリストを for を使って一つずつ取り出して読み込み、処理しています。
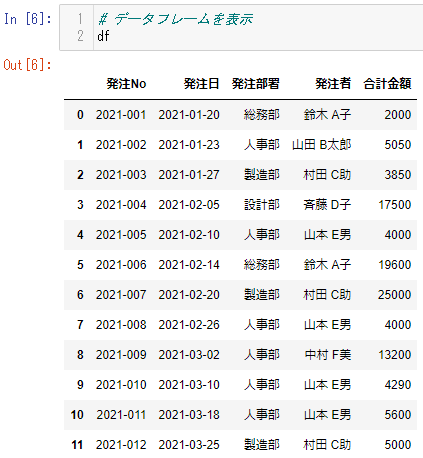
データフレームの中身を表示すると、下記のようにちゃんとエクセルのデータが抽出できています。
抽出したデータの集計
抽出したデータは、Pandas の機能を使って色々な集計や分析が可能です。
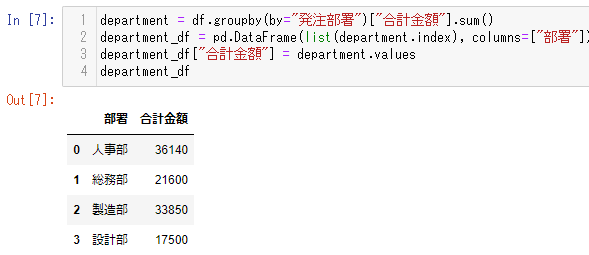
部署ごとの発注金額の集計
例として「部署ごとの発注金額合計」を groupbyメソッドを使って集計するコードを載せておきます
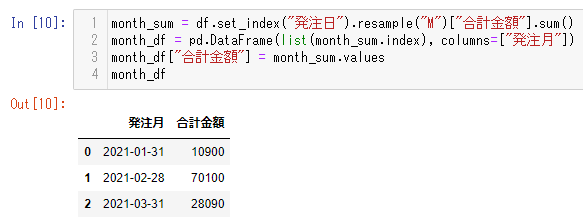
月ごとの発注金額の集計
こちらは「月ごとの発注金額合計」を resampleメソッドを使って集計するコードの例です
まとめ
最後までご覧いただきありがとうございます。
今回は、フォルダ内の複数のエクセルからデータを抽出&集計する方法について解説しました。
- まず globモジュールを使ってフォルダ内のエクセルファイルを取得する
- エクセルから openpyxl を使ってデータを抽出する
- 抽出したデータは Pandas のデータフレームに格納して集計する
思ったよりも簡単なコードだったのではないでしょうか?
是非とも、皆さんがお持ちのエクセルファイルに置き換えて、お仕事に活用していただけますと嬉しく思います。
コメント
業務上やむを得ずPythonでプログラムを作る必要があり苦労中です。
書籍に該当するものがなく、ネットで探していましたところ貴方の
本記事に出会い、まさに探していたものと思い当方のデータに合わせて
作成いたしました。
動作は完全で現状は使える状態に出来ました。
しかしながら常に下記メッセージが出ます。
The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
今後使えなくなるおそれがあるようです。
frame.append methodをpandas.concatに修正する方法をご教示願えないでしょうか。
いくらネットを見て対応しようとしても、さらなるエラーが出ますので苦慮しています。
厚かましいお願いですが、なにとぞよろしくお願いします。
コメントを頂きありがとうございます。
記事中のコードが警告が出る状態になっていたようで、大変失礼いたしました。
下記に修正方法を記載しますので、一度試していただけますと幸いです。
【修正前】
# データフレームに行を追加
df = df.append(wb_data, ignore_index=True)
【修正後】
# データフレームに行を追加
add_df = pd.DataFrame([wb_data])
df = pd.concat([df, add_df], axis=0, ignore_index=True)
早速のご返事ありがとうございました。ご指導のとおり修正しましたところ
問題なく動作し、警告メッセージも一切出ませんでした。
ご回答いただき誠にありがとうございました。